#Sentianalzer
import numpy as np
import matplotlib.pyplot as plt
class SentiAnalyzer:
# Make the method signature to accept "sentidata" and "word"
def __init__(self, sentidata, word):
self.sentidata = sentidata # Original Dataset
self.numTraining = 150 # number of Training
self.wordLimit = 1500 # number of words of interests
self.dataWord = word # list of words
print('This is a senti analyzer')
def runAnalysis(self, idxReview):
probLogPositive = 0
probLogNegative = 0
idxUsedWords, usedWords = self.findUsedWords(idxReview)
for i in range(len(idxUsedWords)):
idxWord = idxUsedWords[i]
positive, negative = self.calculateProbWord(idxWord)
probLogPositive = probLogPositive + np.log(positive)
probLogNegative = probLogNegative + np.log(negative)
positiveProb1, negativeProb1 = self.calculateProbReview()
probLogPositive = probLogPositive + np.log(positiveProb1)
probLogNegative = probLogNegative + np.log(negativeProb1)
# return correct as 1 if the review is positive and the analysis is positive and if the review is negative and the analysis is negative
# return correct as 0 otherwise
# self.dataReviewTesting stores the correct review result by specifying 1 as a positive review
if self.dataReviewTesting[idxReview] == 1:
if probLogPositive > probLogNegative:
correct = 1
else:
correct = 0
else:
if probLogPositive > probLogNegative:
correct = 0
else:
correct = 1
return probLogPositive, probLogNegative, correct
def runWholeAnalysis(self):
cnt = 0
numCorrect = np.zeros((int(self.numTraining/30) + 1, 1))
# for loop with 0, 30, 60, 90, 120, 150
# make
# numCorrect(0) = (sum of correct cases for 0 case) / (size of testing which is 1 in the current iteration)
# numCorrect(1) = (sum of correct cases for 30 case) / (size of testing which is 30 in the current iteration)
# and so on...
for j in range(0,self.numTraining+1,30):
self.dataSentimentTraining = self.sentidata[self.shuffle[0:j+1], 0:self.wordLimit]
self.dataReviewTraining = self.sentidata[self.shuffle[0:j+1], -1]
numCorrect[cnt] = 0
for i in range(np.shape(self.dataSentimentTesting)[0]):
p, n, c = self.runAnalysis(i)
if c == 1:
numCorrect[cnt] += 1
numCorrect[cnt] = numCorrect[cnt] / np.shape(self.dataSentimentTesting)[0]
cnt += 1
return numCorrect
def runExperiments(self, numReplicate):
average = np.zeros((int(self.numTraining/30 + 1), 1))
averageSq = np.zeros((int(self.numTraining/30 + 1), 1))
# iterate by the numReplicate
for i in range(numReplicate):
self.shuffle = np.arange(np.shape(self.sentidata)[0])
np.random.shuffle(self.shuffle)
self.dataSentimentTesting = self.sentidata[self.shuffle[self.numTraining+1:198], 0:self.wordLimit]
self.dataReviewTesting = self.sentidata[self.shuffle[self.numTraining + 1:198], -1]
# receive the correct information from runWholeAnalysis()
correct = self.runWholeAnalysis()
# calculate the average by the training case sizes
average = average + correct
# calculate the squared average by the training case sizes
averageSq += correct * correct
# finish the calculation of average
average = average / numReplicate
# finish the calculation of average squared
averageSq = averageSq / numReplicate
# finish the calculation of standard deviation
std = np.sqrt(averageSq - average * average)
plt.errorbar(np.arange(0, self.numTraining+1, 30), average, std)
plt.title('Product Review Classification')
plt.xlabel('Number of Cases')
plt.ylabel('Percentage of Correct Classification')
plt.show()
def calculateProbWord(self, idxWord):
occurrence = [[row[idxWord]] for row in self.dataSentimentTraining]
positive = np.matmul(np.transpose(occurrence), self.dataReviewTraining)
dataNegReviewTraining = [[1-row] for row in self.dataReviewTraining]
negative = np.matmul(np.transpose(occurrence), dataNegReviewTraining)
positiveProb = int(positive+1) / float(positive+negative+1)
negativeProb = int(negative+1) / float(positive+negative+1)
return positiveProb, negativeProb
def calculateProbReview(self):
numReviews = max(np.shape(self.dataReviewTraining))
positive = np.sum(self.dataReviewTraining)
negative = numReviews - positive
positiveProb = int(positive + 1) / float(numReviews + 1)
negativeProb = int(negative + 1) / float(numReviews + 1)
return positiveProb, negativeProb
def findUsedWords(self, idx):
idxUsedWords = np.where(self.dataSentimentTesting[idx] == 1)[0]
usedWords = self.dataWord[idxUsedWords]
return idxUsedWords, usedWords
################
#main
from SentiAnalyzer import *
import csv
f1 = open('word.csv', 'r', encoding="ISO-8859-1")
rdr1 = csv.reader(f1)
word = []
for row in rdr1:
word.append(row)
f1.close()
word = np.asarray(word)
f2 = open('sentidata.csv', 'r')
rdr2 = csv.reader(f2)
sentidata = []
for row in rdr2:
sentidata.append(row)
f2.close()
sentidata = np.asarray(sentidata, dtype=np.float32)
s = SentiAnalyzer(sentidata, word)
s.runExperiments(3)
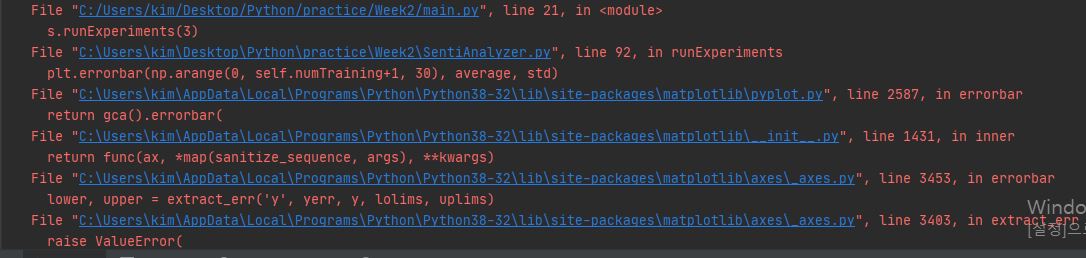

위는 Ch2. 실습코드인데 다음과 같은 에러가 납니다. 에러의 이유를 찾을 수 없어 질문 올립니다
comment